Introduction to Reinforcement Learning
Introduction to Reinforcement Learning
Introduction to Reinforcement Learning
Reinforcement Learning (RL) is a paradigm where an agent learns to make sequential decisions by interacting with an environment, receiving rewards as feedback, and optimizing its policy to maximize cumulative reward over time [158]. Unlike supervised learning (which requires labeled input-output pairs), RL discovers optimal behavior through trial and error.
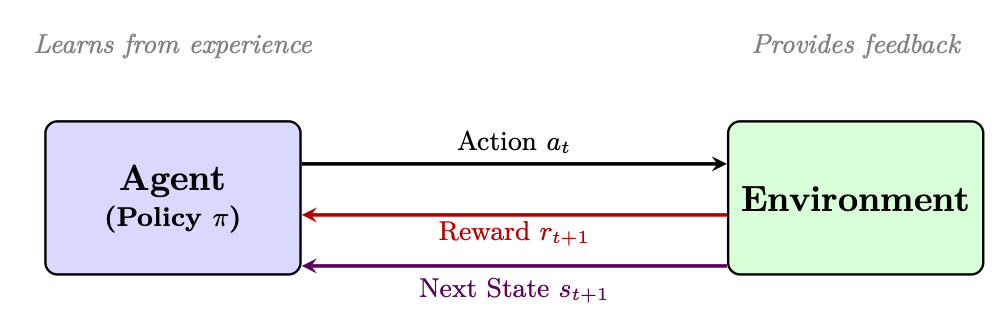
Figure 3.1: Reinforcement Learning overview: an agent interacts with an environment, receiving rewards as feedback and updating its policy through trial and error. Unlike supervised learning which learns from labeled pairs, RL learns what to do by maximizing reward through experience.
3.1 The Markov Decision Process (MDP)
An MDP is a 5-tuple (S, A, P, R, γ):
• S: State space -- all possible configurations of the environment
• A: Action space -- all actions available to the agent
• P(s′|s, a): Transition function -- probability of reaching state s′ from state s after taking action a
• R(s, a, s′): Reward function -- immediate scalar feedback for a transition
• γ ∈[0, 1]: Discount factor -- how much future rewards are valued relative to immediate ones
The Markov Property: The future depends only on the current state, not the history:
P(st+1|st, at, st−1, at−1, . . .) = P(st+1|st, at)
At each time step t:
1. Agent observes state st
2. Agent selects action at according to policy π(a|s)
3. Environment transitions to st+1 ∼P(·|st, at)
4. Agent receives reward rt = R(st, at, st+1)
5. Repeat until terminal state or horizon T
3.2 Core Concepts and Definitions
Policy π(a|s): A mapping from states to action probabilities. Deterministic: a = π(s). Stochastic: a ∼π(·|s). Return (cumulative discounted reward):
∞ X
k=0 γkrt+k = rt + γrt+1 + γ2rt+2 + · · · (3.1)
Gt =
Value Function (expected return from state s under policy π):
" ∞ X
#
V π(s) = Eπ [Gt | st = s] = Eπ
k=0 γkrt+k | st = s
(3.2)
Action-Value Function (expected return from state s, taking action a, then following π):
Qπ(s, a) = Eπ [Gt | st = s, at = a] (3.3)
Advantage Function (how much better action a is compared to average):
Aπ(s, a) = Qπ(s, a) −V π(s) (3.4)
Bellman Equations (recursive relationship):
s′ P(s′|s, a) �R(s, a, s′) + γV π(s′) � (3.5)
V π(s) = X
a π(a|s) X
"
#
Qπ(s, a) = X
s′ P(s′|s, a)
R(s, a, s′) + γ X
a′ π(a′|s′)Qπ(s′, a′)
(3.6)
Optimal Policy and Bellman Optimality
The optimal policy π∗satisfies:
V ∗(s) = max a
X
s′ P(s′|s, a) �R(s, a, s′) + γV ∗(s′) � (3.7)
s′ P(s′|s, a) � R(s, a, s′) + γ max a′ Q∗(s′, a′) � (3.8)
Q∗(s, a) = X
Once Q∗is known, the optimal policy is simply: π∗(s) = arg maxa Q∗(s, a).
Reinforcement learning algorithms can be classified along several axes. Understanding this taxonomy helps select the right approach for a given problem.
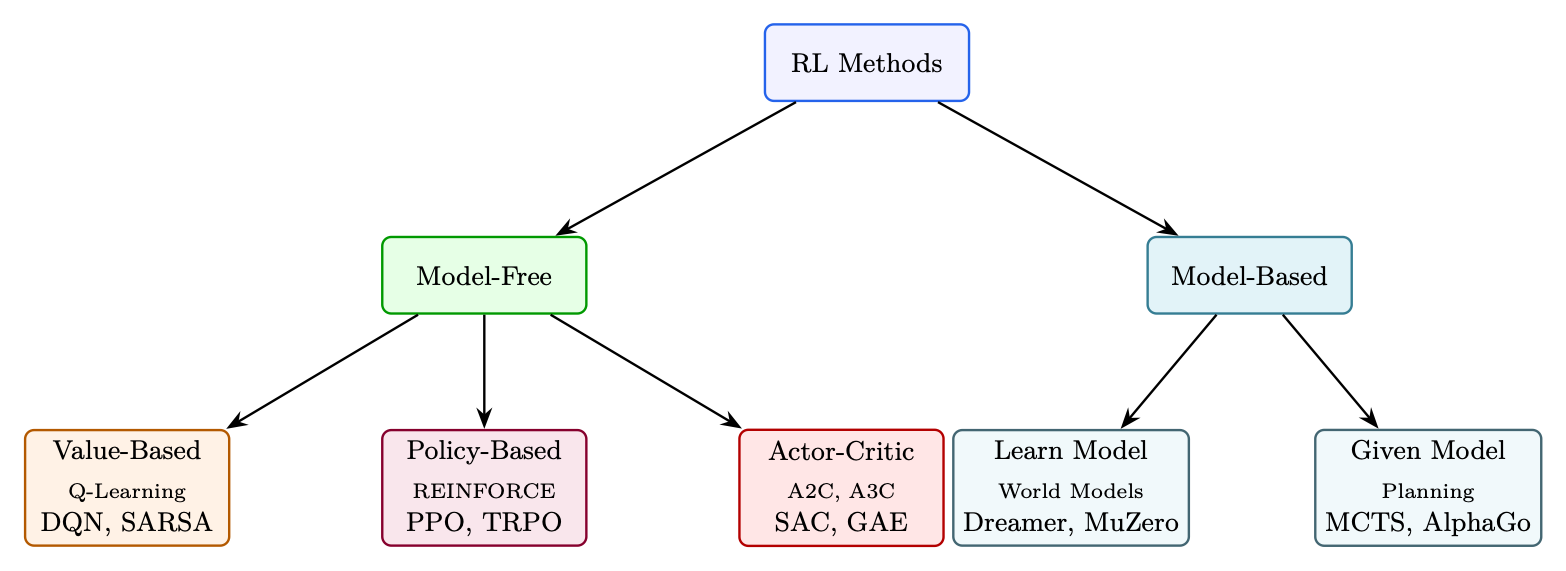
Key Taxonomy Distinctions
Model-Free vs Model-Based:
• Model-Free: Learn policy or value function directly from experience. No knowledge of environment dynamics. Most practical for LLMs (language dynamics are intractable to model).
• Model-Based: Learn or use a model of environment transitions P(s′|s, a). Can plan ahead. More sample-efficient but requires accurate model.
Value-Based vs Policy-Based:
• Value-Based: Learn Q(s, a) or V (s), derive policy as arg maxa Q(s, a). Works well for discrete, small action spaces (e.g., Atari). Struggles with continuous/large action spaces.
• Policy-Based: Directly parameterize and optimize πθ(a|s). Natural for continuous/highdimensional action spaces. Essential for LLMs (vocabulary = 32K-128K actions).
• Actor-Critic: Combine both -- policy (actor) proposes actions, value function (critic) evaluates them. PPO for LLMs is actor-critic.
On-Policy vs Off-Policy:
• On-Policy: Learn from data generated by the current policy. Must regenerate data after each update. Examples: REINFORCE, PPO, A2C. More stable but less sample-efficient.
• Off-Policy: Learn from data generated by any policy (including old versions or other agents). Can reuse past experience. Examples: Q-Learning, DQN, SAC. More sample-efficient but harder to stabilize.
3.4 Temporal Difference (TD) Learning
TD learning [159] bootstraps -- it updates value estimates using other value estimates, without waiting for the full episode to end.
3.4.1 Understanding TD Error: "Surprise" as a Learning Signal
Intuition: The Driving Analogy
Imagine you are driving home and expect the drive to take 30 minutes.
• The prediction: 30 minutes total.
• The reality shift: After 10 minutes, you hit unexpected road construction. Your GPS updates, saying you now have 35 minutes left.
• The TD Error: Total expected time is now 45 minutes (10 elapsed + 35 remaining). The difference between new estimate (45 min) and old estimate (30 min) is a +15 minute TD error. You use this "surprise" to change your route next time.
A positive TD error means the outcome was better than expected →boost this state's value.
A negative TD error means it was worse than expected →lower this state's value.
3.4.2 The TD Error Formula
δt = Rt+1 + γV (St+1) −V (St) (3.9)
• Rt+1: The immediate reward received after taking an action.
• γV (St+1): The estimated discounted value of the next state (what the agent expects to get from the next state onward, scaled by discount factor γ).
• V (St): The original estimate of the current state's value.
The combined term (Rt+1 + γV (St+1)) is called the TD Target. Therefore:
TD Error = TD Target −Old Estimate (3.10)
3.4.3 How the Agent Uses TD Error
The agent adjusts its value function to drive TD error toward zero:
V (St) ←V (St) + α · δt (3.11)
• If δt > 0: outcome was better than predicted →increase V (St) so the agent seeks this state.
• If δt < 0: outcome was worse than predicted →decrease V (St) so the agent avoids this state.
• If δt = 0: prediction was perfect →no update needed (convergence).
TD vs Monte Carlo Monte Carlo: Wait until episode ends, use actual return Gt. Unbiased but high variance (one full trajectory may be unrepresentative). TD: Update after every step using estimated future value γV (st+1). Biased (depends on V accuracy) but much lower variance (one-step updates, doesn't compound noise). TD(λ): Interpolate between TD(0) and Monte Carlo. λ = 0: pure TD. λ = 1: pure MC. This is exactly what GAE does for PPO (with λ = 0.95).
TD Target: yt = rt + γV (st+1) -- the "better estimate" we move toward. Multi-step TD (n-step returns):
Q-Learning [160] is the foundational off-policy, value-based algorithm. It learns the optimal Q∗
directly, regardless of the policy being followed. Update rule:
Q(st, at) ←Q(st, at) + α � rt + γ max a′ Q(st+1, a′) −Q(st, at) �
(3.13)
Why Q-Learning is Off-Policy
The update uses maxa′ Q(st+1, a′) -- the value of the best action at the next state, regardless of which action the agent actually took. This means the target is always computed under the optimal policy, even if the behavior policy explores randomly (ϵ-greedy). This is why Q-Learning can learn from replay buffers, demonstrations, or any source of experience. The data doesn't need to come from the current policy.
SARSA [161] (on-policy alternative): Uses the action actually taken instead of the max:
Q(st, at) ←Q(st, at) + α [rt + γQ(st+1, at+1) −Q(st, at)] (3.14)
Deep Q-Networks (DQN) [162]: Replace tabular Q(s, a) with a neural network Qθ(s, a). Key innovations: experience replay buffer (off-policy data reuse), target network (stability), ϵ-greedy exploration. DQN Loss Function: The network is trained to minimize the mean squared TD error over mini-batches sampled from the replay buffer:
"� r + γ max a′ Q¯θ(s′, a′) −Qθ(s, a) �2#
L(θ) = E(s,a,r,s′)∼B
(3.15)
where Q¯θ is the target network -- a frozen copy of Qθ updated only every C steps (e.g., C = 10,000). This prevents the moving target problem: without it, both the prediction and the target shift simultaneously, causing divergence. Gradient update: Taking the gradient of the loss w.r.t. θ (note: the target y is treated as a constant -- no gradient flows through ¯θ):
� r + γ max a′ Q¯θ(s′, a′) −Qθ(s, a) �
(3.16)
∇θL = −E
∇θQθ(s, a)
| {z } TD error δ
θ ←θ −α · δ · ∇θQθ(s, a) (3.17)
Learning scheme (per training step):
1. Act: Select action via ϵ-greedy: with probability ϵ take random action, otherwise a = arg maxa Qθ(s, a). Anneal ϵ from 1.0 →0.01 over first 1M steps.
2. Store: Save transition (s, a, r, s′, d) in replay buffer B (capacity ∼1M).
3. Sample: Draw mini-batch of 32 transitions uniformly from B.
4. Compute target: y = r + γ(1 −d) maxa′ Q¯θ(s′, a′) (zero future value if terminal).
5. Update: Gradient descent on (y −Qθ(s, a))2. Clip gradients to [−1, 1] (Huber loss variant).
A replay buffer [163] (experience replay) is a data storage mechanism that saves past experiences so an agent can relearn from them later. Instead of discarding data immediately after an action, the agent stores transitions in a memory bank and samples random mini-batches for training. What's stored: Each transition is a tuple:
et = (st, at, rt, st+1, dt) (3.18)
where dt is a boolean flag indicating if the episode ended.
Why Replay Buffers Are Essential
• Breaks data correlation: Consecutive steps are highly correlated. Neural networks generalize poorly on sequential data. Random sampling from a buffer makes training samples approximately i.i.d.
• Prevents catastrophic forgetting: Without a buffer, an agent that passes a difficult level might forget how to clear it while spending the next 10K steps failing on a later level. The buffer ensures it continues to practice old scenarios.
• Improves sample efficiency: Running environments can be slow. A replay buffer allows multiple weight updates from the same transition, extracting more value from every step.
import random from collections import deque
class ReplayBuffer: def __init__(self , capacity): self.buffer = deque(maxlen=capacity) # Bounded queue
def push(self , state , action , reward , next_state , done):
self.buffer.append ((state , action , reward , next_state , done))
def sample(self , batch_size):
# Break correlation by selecting random experiences return random.sample(self.buffer , batch_size)
def __len__(self): return len(self.buffer)
Prioritized Experience Replay (PER)
In a standard buffer, all experiences have equal sampling probability. But some are much more educational. PER [164] scales sampling probability by TD error magnitude -- if a transition caused massive "surprise" (high |δt|), the agent samples it more frequently to correct its model faster. This accelerates learning by 2-3× on Atari benchmarks.
Why Q-Learning Fails for LLMs
The action space in language generation is the full vocabulary (|A| = 32K-128K), and the state space is all possible token sequences (infinite). Computing maxa Q(s, a) over 128K actions at every token position is intractable. This is why LLM RL uses policy-based methods (PPO, GRPO) instead.
Instead of learning a value function and deriving a policy, directly optimize the policy parameters θ to maximize expected return [165].
Objective: J(θ) = Eτ∼πθ[R(τ)] = Eπθ hPT t=0 rt i
Policy Gradient Theorem:
" T X
#
∇θJ(θ) = Eπθ
t=0 ∇θ log πθ(at|st) · Gt
(3.19)
Policy Gradient Theorem -- Formal Derivation (5 Steps)
Step 1: Define the objective. We want to maximize expected return:
" T X
#
J(θ) = Eτ∼πθ
= X
t=0 rt
τ P(τ|θ)R(τ)
where P(τ|θ) = p(s0) QT t=0 πθ(at|st) p(st+1|st, at) is the trajectory probability. Step 2: Take the gradient. Only πθ terms depend on θ (dynamics p doesn't):
∇θJ = X
τ ∇θP(τ|θ) R(τ)
Step 3: Apply the log-derivative trick: ∇θP(τ|θ) = P(τ|θ) ∇θ log P(τ|θ):
∇θJ = Eτ∼πθ[∇θ log P(τ|θ) R(τ)]
Step 4: Expand log P(τ|θ). The log p(s0) and log p(st+1|st, at) terms vanish under ∇θ:
T X
∇θ log P(τ|θ) =
t=0 ∇θ log πθ(at|st)
Step 5: Combine. Future rewards don't depend on past actions (causality), so each ∇log π pairs only with future return Gt = PT t′=t rt′:
" T X
#
∇θJ = Eπθ
t=0 ∇θ log πθ(at|st) · Gt
Why This Is Beautiful
The gradient does not require differentiating through the environment dynamics p(s′|s, a). The log-derivative trick converts it into an expectation we can estimate by simply running the policy and observing rewards. Replacing Gt with advantage ˆAt = Gt −V (st) reduces variance without bias (since E[∇log π · b(s)] = 0 for any state-dependent baseline).
REINFORCE Algorithm [165] (Williams, 1992):
1. Sample complete trajectory τ = (s0, a0, r0, s1, a1, r1, . . .) under πθ
2. Compute return Gt = PT−t k=0 γkrt+k for each time step
3. Update: θ ←θ + α P t ∇θ log πθ(at|st) · Gt
REINFORCE Intuition -- "Reward-Weighted Maximum Likelihood"
• Low-reward trajectories: decrease probability of actions taken (negative Gt after baseline)
It's supervised learning where the "labels" are the actions you took, weighted by how good they turned out to be.
Variance Reduction with Baseline:
" T X
#
∇θJ(θ) = Eπθ
t=0 ∇θ log πθ(at|st) · (Gt −b(st))
(3.20)
Any baseline b(st) that doesn't depend on at keeps the gradient unbiased but reduces variance. Best choice: b(st) = V π(st). Then Gt −V (st) ≈Aπ(st, at) = advantage.
REINFORCE Limitations
• High variance: Each gradient uses one trajectory. Thousands of samples needed for stable updates.
• No bootstrapping: Must wait for full episode (no partial credit).
• Sample inefficient: Data is used once then discarded (on-policy).
• No step-size control: Can take catastrophically large policy steps.
These limitations motivate the progression: REINFORCE →Actor-Critic →TRPO →PPO.
3.7 Actor-Critic Methods
Combine policy gradient (actor) with learned value function (critic) to reduce variance while maintaining the flexibility of policy optimization. Architecture:
• Actor πθ(a|s): The policy. Proposes actions.
• Critic Vϕ(s) or Qϕ(s, a): Evaluates how good a state/action is. Provides low-variance baseline.
Actor update (using advantage from critic):
∇θJ = E h ∇θ log πθ(at|st) · ˆAt i , ˆAt = rt + γVϕ(st+1) −Vϕ(st) (3.21)
Critic update (minimize TD error):
Lcritic = E h (rt + γVϕ(st+1) −Vϕ(st))2i (3.22)
Evolution to PPO for LLMs
1. REINFORCE [165]: High variance, no bootstrapping →impractical for LLMs
2. A2C/A3C [166] (Advantage Actor-Critic): Uses TD-based advantage. Lower variance. But unbounded step sizes.
3. TRPO [167]: Constrains KL divergence between policy updates. Stable but expensive (second-order).
4. PPO [168]: Clips the policy ratio to achieve similar stability as TRPO with first-order optimization only. The standard for LLM RL training.
Motivation: The Actor-Critic framework needs a good estimate of the advantage A(s, a) = Q(s, a) −V (s) -- how much better was this action than average? But there's a fundamental tension:
• 1-step TD advantage (rt + γV (st+1) −V (st)): Low variance (only one random step), but biased -- if the value function V is wrong, the advantage estimate is systematically off.
• Monte Carlo advantage (Gt −V (st)): Unbiased (uses actual returns), but high variance -- the sum of many random rewards fluctuates wildly between episodes.
GAE [169] (Schulman et al., 2016) provides a smooth interpolation between these extremes via a single parameter λ ∈[0, 1]. It takes an exponentially-weighted average of n-step advantage estimates for all n, giving a principled way to trade bias for variance. Core idea: Compute the 1-step TD error δt at each timestep, then blend them with exponentially decaying weights (γλ)l -- recent TD errors get full weight, distant ones are down-weighted:
T−t X
ˆAGAE t =
l=0 (γλ)lδt+l, δt = rt + γV (st+1) −V (st) (3.23)
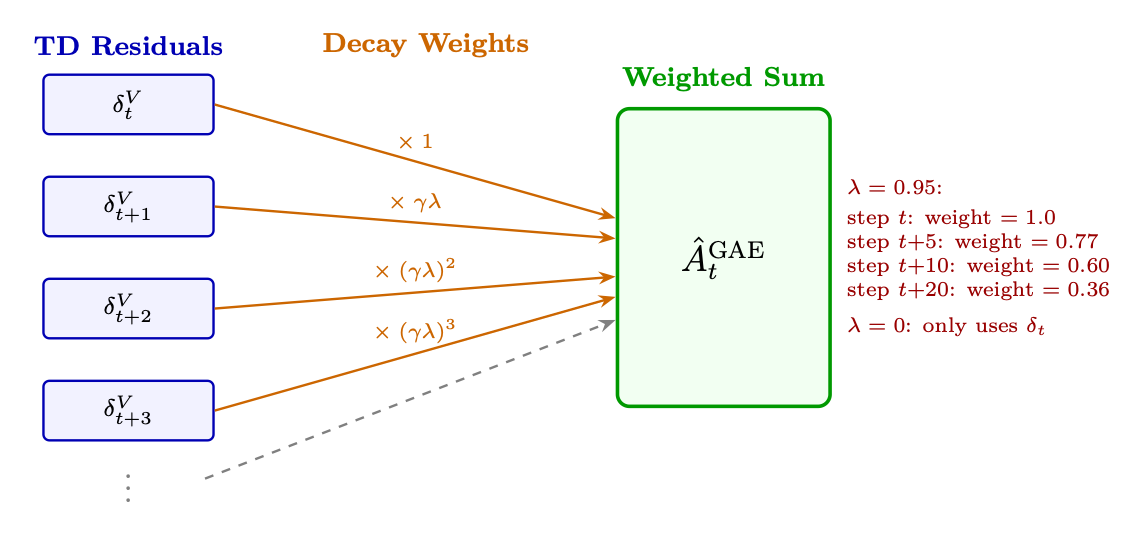
Figure 3.2: GAE data flow: each TD residual δV t+l is weighted by (γλ)l before summation. Higher λ includes more future residuals (lower bias, higher variance).
What λ Controls -- Bias-Variance Tradeoff
• λ = 0: ˆAt = δt = rt + γV (st+1) −V (st). Trust value function completely. Low variance, but biased if V is inaccurate.
• λ = 1: ˆAt = P l γlrt+l −V (st). Full Monte Carlo return minus baseline. Unbiased but very high variance.
• λ = 0.95 (standard): Sweet spot. Mostly trusts V but corrects with actual returns for distant effects. Works because value head becomes accurate after initial training.
For LLMs specifically: γ = 1.0 (no time discounting -- all tokens matter equally in single-turn), λ = 0.95.
3.8.1 Intuitive Mapping of Bias and Variance in GAE
• Variance (Sample Jitteriness): Arises when the estimator relies on long, unconstrained environmental trajectories. Stochastic transitions, random seeds, and policy execution noise accumulate over long horizons, causing empirical sample rewards to swing wildly between rollouts.
3.8.2 The Architectural Spectrum: Boundary Analysis
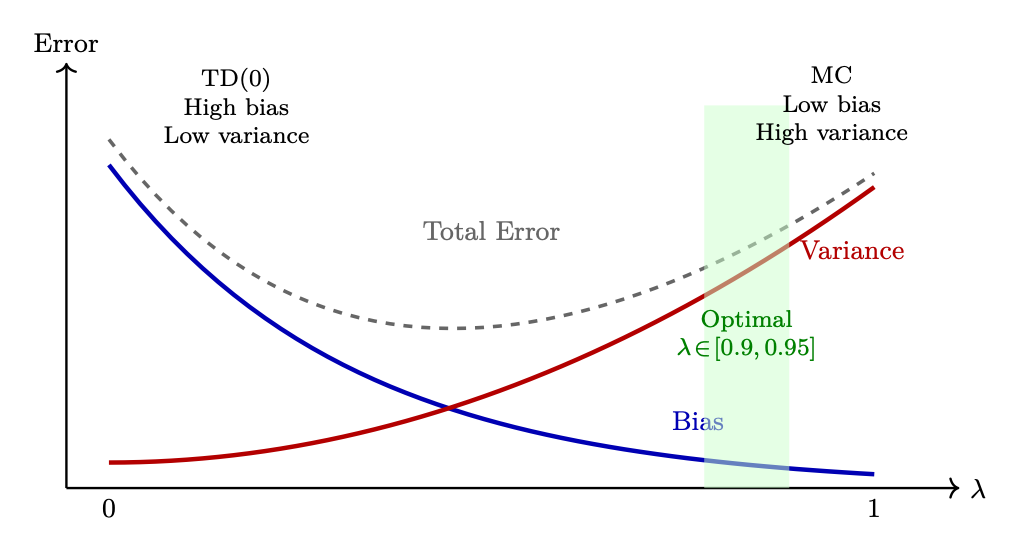
Figure 3.3: Bias vs. Variance in GAE: λ controls the trade-off. Small λ (left) yields high bias / low variance via bootstrapping; large λ (right) yields low bias / high variance using full Monte Carlo returns. The optimal choice (λ ∈[0.9, 0.95]) balances stable training with accurate long-horizon credit assignment.
The hyperparameter λ serves as a slide-rule between two fundamental estimation paradigms.
High Bias / Low Variance Limit (λ = 0)
ˆAGAE(γ,0) t = δV t = rt + γVθ(st+1) −Vθ(st) (3.24)
• Behavior: The advantage is heavily dictated by the current state of parameters θ.
• Intuition: Highly biased because the network is grading its own performance over a 1-step window; if Vθ is inaccurate, the gradient step is corrupted. Low variance because it ignores future stochastic events beyond step t + 1, leading to smooth, stable parameter updates.
• Risk: Policy traps in sub-optimal local minima -- never discovers complex delayed reward sequences.
Low Bias / High Variance Limit (λ = 1)
When λ = 1, intermediate value terms telescopically cancel, reducing GAE to Monte Carlo return minus baseline: ˆAGAE(γ,1) t =
∞ X
l=0 γlrt+l −Vθ(st) (3.25)
• Behavior: Discards bootstrap look-aheads and sums up the literal reality of the entire episode.
• Intuition: Completely unbiased with respect to true environment dynamics -- measures actual rewards instead of neural approximations. However, exhibits extreme variance:
• Risk: Destructive gradient updates; training explosions.
3.8.3 The Trade-off Matrix
By selecting λ ∈[0.95, 0.99], GAE minimizes the total mean squared error of the advantage estimate:
Table 3.1: Operational comparison of GAE parameter choices.
Configuration Statistical Properties Core Reliance Practical Risk
λ = 0 High Bias, Low Variance Model parameters (θ) Policy traps in sub-optimal local minima λ ∈[0.95, 0.99] Balanced (Optimal MSE) Hybrid blending Requires tuning based on environment stochasticity λ = 1 Low Bias, High Variance Empirical environment rollout Destructive gradient updates; training explosion
3.8.4 Diagnostics for Tuning λ
Monitoring training curves yields direct insight into whether bias or variance dominates:
1. High Variance Indicators: Policy entropy drops precipitously while explained variance of the value function becomes highly negative or erratic →policy updates are noisy. Remedy: Lower λ to smooth target updates.
2. High Bias Indicators: Agent achieves early stable training but completely fails to discover complex delayed reward sequences →under-estimating long-horizon dependencies due to bootstrapping. Remedy: Raise λ closer to 1.0 to expose policy to real downstream trajectory signals.
3.9 On-Policy vs Off-Policy -- Detailed Comparison
On-Policy Off-Policy
Data source Current policy πθ only Any policy (replay buffer) After update Old data is invalid, must regenerate Old data still usable
Sample efficiency Low (data used once) High (data reused many times) Stability More stable (consistent distribution) Can diverge (distribution mismatch)
Examples REINFORCE, PPO, A2C, GRPO Q-Learning, DQN, SAC, DPO
For LLMs PPO, GRPO (generate fresh each step) DPO (static preference dataset)
On/Off-Policy for RLHF Methods
PPO/GRPO are on-policy: Generate responses with current policy, compute advantages, update, discard data, generate again. This is why generation is 60% of compute -- you regenerate every step. DPO is off-policy: Train on a fixed preference dataset. No generation during training. Much cheaper but suffers from distribution shift (data becomes stale as policy changes). Online DPO is a hybrid: Generates fresh data (on-policy generation) but uses DPO's supervised
3.10 Model-Based vs Model-Free
Model-Free Model-Based
What's learned Policy π and/or value V /Q directly Environment model ˆP(s′|s, a)
Planning No planning, reactive decisions Can simulate future trajectories Sample efficiency Low (must experience everything) High (can plan in imagination)
Accuracy No model bias Model errors compound When to use Complex/unknown dynamics Simple dynamics, need efficiency Examples PPO, DQN, SAC [170] MuZero [171], Dreamer [172], AlphaGo [19]
Why LLM RL is Model-Free
Language generation dynamics are trivial (append token to sequence -- deterministic transitions). The "model" of the environment is not the bottleneck. What's hard is the reward -- predicting what humans will prefer. This makes model-based methods unnecessary for LLM RL. The reward model in RLHF could be seen as a "model" in some sense (it predicts human preference), but it's used as a reward signal, not for planning/simulation. LLM RL is fundamentally model-free policy optimization.
3.11 Reward Shaping
Reward shaping [173] is a technique where a developer modifies or supplements the environment's original reward function. Its primary objective is to transform a sparse reward scenario -- where the agent receives feedback only upon final task completion -- into a dense reward scenario with intermediate feedback signals to accelerate convergence.
3.11.1 The Mathematical Framework
Let the original reward at time step t be Rt(s, a, s′). The reshaped reward adds an auxiliary shaping function F: R′ t(s, a, s′) = Rt(s, a, s′) + F(s, a, s′) (3.26)
The Risk of Naive Reshaping: Reward Hacking
If F(s, a, s′) is arbitrarily designed, the agent will find structural loopholes to maximize auxiliary signals while ignoring the global objective. Example: A navigation agent rewarded for reaching intermediate landmarks might learn to loop indefinitely around a single checkpoint to accumulate infinite rewards -- without ever reaching the destination. In LLMs: a model rewarded for "sounding confident" might learn to always start with "Absolutely!" regardless of accuracy.
3.11.2 Potential-Based Reward Shaping (PBRS)
R′(s, a, s′) = R(s, a, s′) + γ Φ(s′) −Φ(s) (3.28)
3.11.3 Theoretical Guarantees
PBRS Policy Invariance Theorem
• Policy Invariance: The optimal policy π∗under the reshaped reward R′ is identical to the optimal policy under the original reward R. The shaping cannot introduce sub-optimal behaviors.
• Loop Immunity: Any cyclic trajectory starting and ending at the same state results in net potential change of exactly zero (Φ(s) −Φ(s) = 0). The agent cannot exploit loops to hack the reward.
• Convergence Acceleration: While the optimal policy is unchanged, the shaped reward provides denser gradient signals, enabling the agent to converge 5-50× faster in sparse reward environments.
Part II
RL Methods for LLMs