PPO — Proximal Policy Optimization
PPO — Proximal Policy Optimization
Chapter 5
PPO -- Proximal Policy Optimization
5.1 Motivation and History
Problem: Vanilla policy gradient updates have no constraint on step size. A single unlucky batch can push the policy into a region where it generates garbage →garbage gets low rewards →next gradient makes things worse →unrecoverable collapse. Solution history:
1. TRPO [167] (2015): Constrain KL divergence between old and new policy. Works perfectly but requires expensive second-order optimization (Fisher information matrix, conjugate gradients).
2. PPO (2017) [168]: Achieve similar stability with a simple first-order clipped objective. 10× simpler to implement, works almost as well, scales to distributed training trivially.
5.2 The Clipped Objective
The core innovation of PPO is a clipped surrogate objective that prevents destructively large policy updates while remaining simple to implement.
LCLIP(θ) = Et h min � rt(θ) ˆAt, clip(rt(θ), 1−ϵ, 1+ϵ) ˆAt �i
(5.1)
where rt(θ) = πθ(at|st) πθold(at|st) is the probability ratio.
Clipping Intuition -- The Key Insight
The min operator creates a pessimistic bound:
• Good action ( ˆA > 0): We want to increase its probability. The surrogate r ˆA grows as r increases. But clip caps benefit at r = 1 + ϵ. "Don't get greedy on one good example."
• Bad action ( ˆA < 0): We want to decrease its probability. r ˆA improves as r decreases. But clip caps benefit at r = 1 −ϵ. "Don't forget too aggressively based on one bad example."
Net effect: policy changes by at most ±20% per update step. Prevents both catastrophic collapse and overconfident specialization.
5.3 Full PPO Loss
L = LCLIP −c1 (Vθ(st) −V target t )2 | {z } value loss
+c2 H[πθ(·|st)] | {z } entropy bonus
(5.2)
5.4 Derivation of the PPO Gradient and Update Rule
This section traces the mathematical path from the RL objective to the PPO update rule, showing why the clipped surrogate works.
5.4.1 Step 1: The RL Objective
The goal is to maximize expected cumulative reward under the policy:
" T X
#
J(θ) = Eτ∼πθ
t=0 rt
(5.3)
5.4.2 Step 2: Policy Gradient Theorem
The gradient of J(θ) with respect to policy parameters:
" T X
#
∇θJ(θ) = Eπθ
t=0 ∇θ log πθ(at|st) · ˆAt
(5.4)
where ˆAt is the advantage function (how much better action at was compared to the average action in state st). This replaces the full return with the advantage to reduce variance.
5.4.3 Step 3: Importance Sampling for Off-Policy Data
PPO collects data using πθold but updates πθ. To correct for this distribution mismatch, apply importance sampling:
" πθ(at|st) πθold(at|st)∇θ log πθ(at|st) · ˆAt
#
∇θJ(θ) = Eπθold
(5.5)
Define the probability ratio rt(θ) = πθ(at|st) πθold(at|st). Using the identity ∇θ log f = ∇θf
f , we get:
h ∇θ rt(θ) · ˆAt i (5.6)
∇θJ(θ) = Eπθold
This means maximizing the surrogate objective:
LCPI(θ) = Et h rt(θ) · ˆAt i (5.7)
5.4.4 Step 4: The Problem with Unconstrained Surrogates
LCPI is a valid objective, but without constraints, a single gradient step can push rt(θ) far from 1.0, causing:
• Importance weights become extreme →high variance
• Policy enters untested regions →reward model gives unreliable scores
• Catastrophic collapse: policy generates garbage, can't recover
PPO replaces the hard KL constraint with a clipped objective that achieves similar behavior using only first-order gradients:
LCLIP(θ) = Et h min � rt(θ) ˆAt, clip(rt(θ), 1−ϵ, 1+ϵ) ˆAt �i
(5.8)
Derivation of the gradient: Let Lt = min(rt ˆAt, ¯rt ˆAt) where ¯rt = clip(rt, 1−ϵ, 1+ϵ).
( ∇θrt(θ) · ˆAt if rt ˆAt < ¯rt ˆAt (unclipped term is smaller) 0 if rt ˆAt ≥¯rt ˆAt (clipped term is smaller, gradient = 0) (5.9)
∇θLt =
Expanding the conditions:
• When ˆAt > 0 and rt < 1 + ϵ: Gradient flows normally -- policy is encouraged to increase πθ(at|st).
• When ˆAt > 0 and rt ≥1 + ϵ: Gradient is zero -- policy has already increased enough, stop pushing.
• When ˆAt < 0 and rt > 1 −ϵ: Gradient flows normally -- policy is encouraged to decrease πθ(at|st).
• When ˆAt < 0 and rt ≤1 −ϵ: Gradient is zero -- policy has already decreased enough, stop pushing.
5.4.6 Step 6: The Complete PPO Update Rule
Combining the clipped policy loss, value loss, and entropy bonus:
θk+1 = θk + α · ∇θ h LCLIP(θ) −c1LVF(θ) + c2H[πθ] i
(5.10)
where:
LVF(θ) = � Vθ(st) −V target t �2 (value function regression loss) (5.11)
H[πθ] = − X
a πθ(a|st) log πθ(a|st) (entropy of the policy) (5.12)
Summary: Why This Works
1. Policy gradient theorem gives us the direction to improve the policy.
2. Importance sampling lets us reuse data from πθold across multiple epochs.
3. Clipping prevents the importance weights from becoming extreme, keeping updates safe.
4. The min operator ensures we always take the more conservative of (clipped, unclipped) -- a pessimistic lower bound on improvement.
5. Result: Monotonic improvement with probability 1, using only first-order gradients. No Hessians, no conjugate gradients, no line searches.
5.5 Rollout Buffer and Rollouts
A rollout (trajectory) is a sequence of interactions generated by the agent running its current policy in the environment:
• The process: The agent observes a state, selects an action, receives a reward, and moves to the next state. It repeats for a fixed number of steps or until the episode ends.
• In LLMs/RLHF: A rollout consists of taking a prompt from a dataset and letting the language model generate a complete sequence of tokens token-by-token until an end-of-text marker is hit. Each token is one "step."
5.5.2 The Rollout Buffer
The rollout buffer temporarily stores all data collected during the rollout phase. For every generated token/step, it records:
B = {(st, at, log πθold(at|st), rt, V (st))}T t=1 (5.13)
• st, at, rt: State, action taken, and reward at step t.
• log πθold(at|st): Log-probability of taking that action under the exact policy that generated it (needed for ratio computation).
• V (st): Value function's baseline prediction (needed for GAE advantage computation).
5.5.3 The Rollout Buffer Lifecycle
The buffer operates in a strict three-phase clockwork cycle:
1. Collect: The active policy interacts with the environment to fill the buffer with fresh trajectories (for a 70B model with batch=128, max_tokens=512: up to 65K token-level transitions per rollout).
2. Train: Compute GAE advantages across trajectories. Run K epochs (typically 3-10) of mini-batch gradient descent to update policy weights using the clipped objective.
3. Purge: The entire buffer is completely wiped clean. Because PPO is on-policy, data generated by the old policy cannot be safely reused for the next update cycle -- the ratio rt(θ) would become stale and the clipping guarantees would break.
Rollout Buffer vs Replay Buffer
Replay Buffer (DQN, SAC): Off-policy. Stores millions of transitions indefinitely. Random sampling. Data reused across many updates. Rollout Buffer (PPO, GRPO): On-policy. Stores one batch of trajectories. Used for a few epochs, then discarded entirely. Fresh data required every cycle. This is why PPO requires continuous generation -- the buffer is emptied after every update, demanding fresh rollouts. This makes the generation bottleneck (60-70% of wall-clock time) particularly painful.
vLLM in RLHF Context In RLHF training, vLLM is used for the generation phase (60-70% of wall-clock time). The policy model generates rollouts that are then scored by the reward model. Key benefits:
• Batched generation: Generate 256+ responses in parallel across prompts.
• Memory efficiency: Fit more concurrent generations →higher GPU utilization during the generation bottleneck.
• Integration: Frameworks like OpenRLHF and TRL use vLLM as the generation backend, separating generation workers (vLLM) from training workers (DeepSpeed/FSDP).
5.6 PPO for RLHF: The Full Loop

Concrete PPO Step for a 70B Chat Model
Setup: Batch of 128 prompts, Llama-3-70B policy, 512 max tokens. Step 1 -- Generate: Sample 128 responses (temperature=0.7, top-p=0.9). This takes 60% of time. Step 2 -- Score: Reward model scores each (prompt, response) pair. Range: 0.2-0.95. Step 3 -- KL: Compute per-token KL: KLt = log πθ(yt|y<t) −log πref(yt|y<t). Mean KL across tokens: typically 3-8. Step 4 -- Final reward: R = rRM −0.05 × mean_KL (only at last token). Step 5 -- GAE: Compute ˆAt for each token position using value head predictions. Whiten advantages (zero mean, unit variance). Step 6 -- Update: 4 epochs of SGD on mini-batches of 16. Clip ratio ϵ = 0.2. Gradient norm clipping at 1.0. Result: Policy improves by ∼0.005 win-rate per step. After 10K steps: 5-10% absolute improvement over SFT.
Tokenization Pitfalls in RL for LLMs When computing per-token KL penalties and advantages, remember that tokenization determines what a "step" is. A single conceptual action (e.g., outputting "2024") might span 1-4 tokens depending on the tokenizer. This creates subtle issues:
• KL accounting: Per-token KL sums to different totals for the same semantic content tokenized differently (e.g., rare words split into more subwords get higher total KL penalty).
• Credit assignment: GAE assigns advantage per token position--but semantic "decisions" often span multiple tokens. The model only truly "decides" at the first token of a word; subsequent subword tokens are largely deterministic.
• Reward placement: Placing reward only at the final token means all preceding tokens must propagate credit backward through GAE--longer responses suffer from more diluted signal.
Mitigation: Some systems normalize KL by sequence length, use word-level reward shaping, or apply reward at semantic boundaries rather than the final token.
5.7 Detailed Mechanics: Logits and Policy Updates
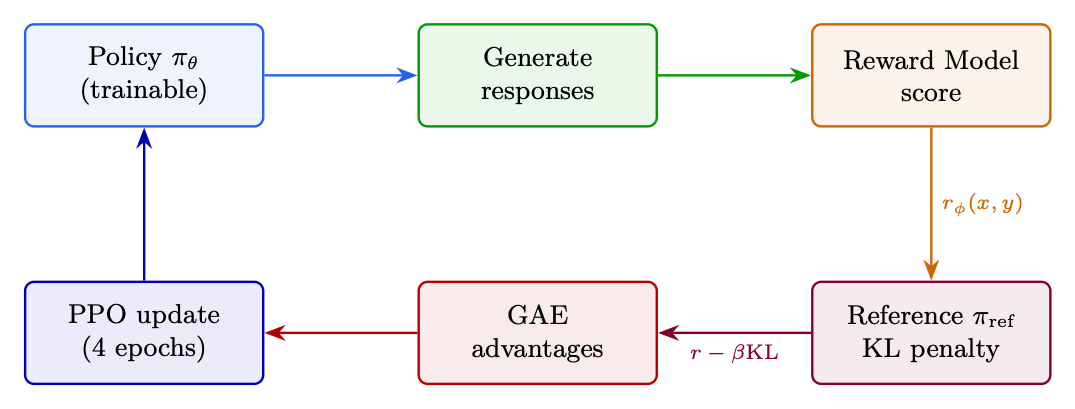
Figure 5.1: PPO end-to-end: from prompt batch through generation, reward scoring, KL computation, advantage estimation, to clipped policy update. The feedback loop shows the updated policy being used for the next generation step.
Core Architecture: Two Networks
1. The Policy Network (πθ): The active, live network parameterized by weights θ. Continuously updated via backpropagation during optimization.
2. The Old Policy Network (πθold): A frozen snapshot parameterized by weights θold. Acts as a static anchor during a single optimization cycle to prevent the policy from shifting too drastically.
5.7.1 Phase 1: Rollout (Data Collection)
During data collection, the agent interacts with the environment for T steps. At each time-step t:
1. The environment yields the current state/observation st (for LLMs: prompt + tokens generated so far).
2. State st is passed through the current network snapshot (θold).
3. The network outputs raw unnormalized values -- logits zold -- a vector of size |V | (vocabulary size 32K-128K).
4. Probabilities are computed via Softmax:
P(a | st) = Softmax(zold) = exp(zold,a) P|V | j=1 exp(zold,j)
(5.14)
5. An action at (next token) is sampled from P(a | st), and the transition tuple ⟨st, at, rt, st+1⟩ along with log πθold(at | st) is stored in the rollout buffer.
Why Store Log-Probabilities?
Storing log πθold(at | st) as a scalar during rollout avoids re-running the frozen network during optimization. This saves one full forward pass per mini-batch -- significant for 70B models.
5.7.2 Phase 2: Optimization Loop (Mini-Batch Updates)
Once the rollout buffer is full, PPO runs K epochs (typically 3-10) over mini-batches. For every gradient step, logits are generated for both policies using the stored state st: Old Policy Evaluation (frozen):
zold = f(st; θold) −→ log πθold(at | st) = LogSoftmax(zold)[at] (5.15)
znew = f(st; θ) −→ log πθ(at | st) = LogSoftmax(znew)[at] (5.16)
Because θ updates after every mini-batch gradient step, znew changes continuously throughout the optimization loop, whereas zold remains perfectly static.
5.7.3 From Logits to Probability Ratio
The core PPO ratio measures how much more or less likely an action is under the new policy vs the old:
rt(θ) = πθ(at | st) πθold(at | st) (5.17)
To avoid catastrophic numerical underflow/overflow from dividing raw probabilities, the calculation is performed in log-space:
log πθ(at | st) = LogSoftmax(znew)[at] (5.18)
log πθold(at | st) = LogSoftmax(zold)[at] (5.19)
The ratio is recovered via exponentiation of the difference:
rt(θ) = exp(log πθ(at | st) −log πθold(at | st)) (5.20)
This ratio is injected into the PPO clipping objective:
LCLIP(θ) = ˆEt h min � rt(θ) ˆAt, clip(rt(θ), 1−ϵ, 1+ϵ) ˆAt �i
(5.21)
How Clipping Works
• If ˆAt > 0 (good action): ratio is clipped at 1 + ϵ -- cannot over-exploit good actions.
• If ˆAt < 0 (bad action): ratio is clipped at 1 −ϵ -- cannot over-penalize bad actions.
• The min(·) ensures we always take the more conservative estimate.
Result: monotonic improvement within a trust region -- no catastrophic collapses.
5.7.4 The PPO Weight Lifecycle
Table 5.1: Evolution of θ and θold across PPO training phases.
Phase Live θ Old θold Ratio rt(θ)
1. Rollout Start Active copy Same active copy Always 1.0 (by identity) 2. Batch Step 1 Computes gradients Frozen 1.0 (initial step) 3. Batch Step N Modifying (θ ̸= θold) Frozen Deviates from 1.0 (e.g., 1.06, 0.94) 4. Clipping Active Bounded by ϵ Frozen Trapped at bound (1 ± ϵ) 5. Optimization End Highly optimized Discarded N/A 6. Next Cycle θ →θold Receives fresh θ Resets back to 1.0
5.7.5 Continuous Action Spaces Extension
For continuous action spaces (not typical for LLMs, but important for robotics RL), the network outputs distribution parameters instead of discrete logits:
Log-probabilities are computed via the Gaussian log-PDF:
�2 −log(σ) −1
log π(at | st) = −1
�at −µ
2 log(2π) (5.22)
σ
The ratio rt(θ) = exp(log πθ −log πθold) is then computed identically and fed into the same clipping objective.
5.8 TRL Implementation
The HuggingFace TRL library [176] provides production-ready implementations of all major RL methods for LLMs.
from trl import PPOConfig , PPOTrainer , AutoModelForCausalLMWithValueHead from transformers import AutoTokenizer from peft import LoraConfig
# Model setup model = AutoModelForCausalLMWithValueHead . from_pretrained (
"meta -llama/Llama -3.1 -8B-Instruct", torch_dtype=torch.bfloat16 , device_map="auto", peft_config=LoraConfig(r=64, lora_alpha =16, target_modules =["q_proj","v_proj", "k_proj","o_proj"]) ) tokenizer = AutoTokenizer. from_pretrained ("meta -llama/Llama -3.1 -8B-Instruct")
# PPO config with all critical hyperparameters ppo_config = PPOConfig(
learning_rate =1.5e-6, # Low LR for stability batch_size =128, # Prompts per step mini_batch_size =16, # Gradient accumulation unit ppo_epochs =4, # Epochs per batch (reuse data) gamma =1.0, # No discounting (single turn) lam =0.95 , # GAE lambda cliprange =0.2, # PPO epsilon cliprange_value =0.2, # Value function clipping vf_coef =0.1, # Value loss coefficient init_kl_coef =0.05 , # Initial KL penalty target_kl =6.0, # Adaptive KL target whiten_rewards =True , # Normalize advantages gradient_accumulation_steps =4, max_grad_norm =1.0, )
ppo_trainer = PPOTrainer(config=ppo_config , model=model , tokenizer=tokenizer ,
dataset=prompt_dataset , data_collator =collator)
# Training loop for batch in ppo_trainer.dataloader:
# 1. Generate responses query_tensors = batch["input_ids"] response_tensors = ppo_trainer.generate(
query_tensors , max_new_tokens =512 , temperature =0.7 , top_p =0.9 , do_sample= True
) # 2. Score with reward model texts = [tokenizer.decode(r, skip_special_tokens =True) for r in response_tensors ]
rewards = [torch.tensor(reward_model .score(q, r)) for q, r in zip(batch["query "], texts)]
5.9 Critical Hyperparameters
Parameter Typical Effect of Getting It Wrong
cliprange 0.2 Too low: no learning. Too high: instability. init_kl_coef 0.01-0.1 Too low: reward hacking. Too high: stuck at SFT. target_kl 4-8 Adaptive controller target. Lower = conservative. ppo_epochs 4 Too many: overfits to batch. Too few: wastes gen compute. learning_rate 1−5 × 10−6 Too high: catastrophic forgetting. batch_size 64-256 Larger = smoother gradients, more gen compute. temperature 0.7-1.0 Lower: less exploration. Higher: noisier advantages.
Chapter 6
DPO -- Direct Preference Optimization
6.1 Motivation
PPO requires 4 models in memory (policy, reference, reward model, value head), complex RL infrastructure, and is notoriously unstable. DPO [10] asks: can we skip the RL and learn directly from preferences? Key insight: The optimal policy under the RLHF objective (reward maximization + KL penalty) has a closed-form solution. We can derive a supervised loss that implicitly optimizes the same objective.
6.2 Mathematical Derivation
Step 1: RLHF objective: maxπ Ex,y∼π[r(x, y)] −βDKL[π∥πref]
Step 2: The optimal solution is: π∗(y|x) = 1 Z(x)πref(y|x) exp � r(x,y)
�
β
Step 3: Rearrange to express reward in terms of policy: r(x, y) = β log π∗(y|x)
πref(y|x) + β log Z(x) Step 4: Substitute into Bradley-Terry preference model P(yw ≻yl) = σ(r(yw) −r(yl)). The Z(x) cancels!
� log σ � β log πθ(yw|x)
πref(yw|x) −β log πθ(yl|x)
��
LDPO(θ) = −E(x,yw,yl)
(6.1)
πref(yl|x)
What DPO Actually Does
Define the implicit reward as ˆr(x, y) = β log πθ(y|x)
πref(y|x). DPO minimizes the cross-entropy loss where the "label" is: chosen should have higher implicit reward than rejected. The margin is controlled by β:
• Large β: need large margin →policy moves aggressively →risk forgetting
• Small β: small margin suffices →policy stays close to reference →conservative
The reference model acts as a regularizer: the policy must "justify" any deviation from it by showing preference alignment.
6.3 Gradient Analysis
The DPO gradient decomposes as:
· [∇θ log πθ(yw|x) −∇θ log πθ(yl|x)] (6.2)