Introduction
Introduction
Introduction
The Big Picture
This guide takes you from first principles to production systems. It is written for practitioners -- researchers, engineers, and applied scientists -- who want to understand and build the full stack of modern AI: from transformer architectures and the hardware that runs them, through the training algorithms that align models with human intent and teach them to reason, to the agentic architectures that deploy them as autonomous systems. The core thesis is simple: building great AI systems requires understanding the entire pipeline, not just one layer. An engineer debugging a training run needs to understand GPU memory hierarchies and optimizer dynamics. A fine-tuning practitioner needs to know when LoRA suffices and when full-parameter training is worth the cost. An agent developer needs to understand how the underlying model was trained. A technical leader evaluating frameworks needs to understand what trade-offs each one makes. This guide provides that complete picture.
The Road to Agentic AI: A Brief History
Today's agentic AI systems did not emerge in a vacuum. They stand on decades of milestone systems -- each solving a narrower problem but collectively building the techniques, hardware, and ambition that made autonomous agents possible.
1. Deep Blue (1997) [16] -- IBM's chess engine defeated world champion Garry Kasparov using brute-force search (200 million positions/second) with handcrafted evaluation functions. It proved machines could exceed human performance in well-defined adversarial domains, but generalized to nothing else.
2. IBM Watson -- Jeopardy! (2011) [17] -- Watson combined information retrieval, NLP, and massive parallelism to defeat human champions at open-domain question answering. It demonstrated that AI could process unstructured text at scale, but required years of domainspecific engineering and couldn't learn new domains without substantial human effort.
3. AlexNet and the Deep Learning Revolution (2012) [18] -- Krizhevsky et al.'s CNN won ImageNet by a stunning margin, proving that deep neural networks trained on GPUs could learn representations from raw data. This single result triggered the modern deep learning era and the hardware investment that eventually made LLMs possible.
4. AlphaGo (2016) [19] -- DeepMind's system defeated Go world champion Lee Sedol using deep RL (policy networks + value networks + Monte Carlo Tree Search). Unlike Deep Blue's brute force, AlphaGo learned to play -- demonstrating that RL could master domains where search alone was intractable (10170 board states). AlphaGo Zero (2017) [20] later learned entirely from self-play, needing no human games at all.
7. ChatGPT and RLHF (2022) [9] -- InstructGPT/ChatGPT proved that a capable base model, when aligned via RLHF, becomes a genuinely useful assistant. This was the inflection point: AI went from a research tool to a consumer product used by hundreds of millions. The alignment techniques (reward models, PPO) became the template for all subsequent LLM post-training.
8. GPT-4 and Multimodal Models (2023) [23] -- Multimodal capabilities (vision + language), longer contexts, and improved reasoning pushed LLMs toward general-purpose cognition. Tool use (code interpreter, web browsing) hinted at agentic capabilities.
9. Reasoning Models (2024) [15] -- OpenAI's o1 and DeepSeek-R1 showed that RL could teach models to reason: chain-of-thought, backtracking, self-verification emerged spontaneously from reward signals alone. Models began solving competition-level mathematics and complex coding tasks.
10. Agentic AI (2025-present) -- The convergence point: LLMs with reasoning capabilities, equipped with standardized tool access (MCP), inter-agent communication (A2A), persistent memory, and sophisticated orchestration frameworks. Agents now autonomously write code, conduct research, manage workflows, and coordinate with other agents -- the subject of this guide.
Each milestone shares a common arc: architecture innovation + scale + learning signal = breakthrough. Deep Blue used handcrafted search. AlphaGo learned from self-play. GPT-3 learned from internet text. Today's agentic systems learn from human feedback, verifiable rewards, and environment interaction. The learning signal has expanded from game outcomes to open-ended human preferences -- and the architectures have grown to match.
This guide picks up the story at the foundation model era and carries it forward through alignment, reasoning, and autonomous agency.
What You Should Expect
Part I: Foundations (Chapters 1-3) builds the base knowledge the rest of the guide depends on. We start with how LLMs work internally -- the architecture decisions that determine capability -- then cover the hardware and systems that make training and inference possible, and finally introduce reinforcement learning from first principles.
• Chapter 1 -- LLM Architecture and Optimization: Transformer internals (self-attention, multi-head attention, RoPE, GQA), Flash Attention, optimization methods (AdamW, learning rate schedules, gradient clipping), mixed precision, LoRA/QLoRA, quantization, knowledge distillation, and Mixture of Experts.
• Chapter 2 -- Systems Foundations: GPU architecture (A100/H100/B200), memory hierarchies, NVLink/NVSwitch, distributed training (FSDP, DeepSpeed ZeRO, tensor/pipeline parallelism), and vLLM for high-throughput inference.
• Chapters 4-8: Every major RL/preference algorithm with math, intuition, and TRL code -- PPO, DPO, GRPO, and preference optimization variants (Online DPO, KTO, IPO, ORPO, SimPO, Best-of-N).
• Chapters 9-10: Reward model training (Bradley-Terry, scaling laws, reward hacking) and SFT best practices (data quality, curriculum, formatting).
• Chapters 11-12: System architecture at scale (decoupled training, fault tolerance, GPU allocation) and LLM agentic training -- how to train agents end-to-end with trajectory-level RL.
Part III: Reasoning (Chapter 13) covers the frontier of model capability -- teaching LLMs to reason through multi-step problems.
• Chapter 13 -- RL for Large Reasoning Models: DeepSeek-R1, OpenAI o1/o3/o4-mini, QwQ -- how RL discovers chain-of-thought, MCTS, process reward models, and test-time compute scaling.
Part IV: Evaluation (Chapter 14) provides the methodology for measuring whether any of this actually works.
• Chapter 14 -- LLM Evaluation: Metrics (perplexity, pass@k, ELO), LLM-as-Judge patterns, contamination detection, benchmark suites, and agentic evaluation methodology.
Part V: Agentic AI (Chapters 15-26) takes you from a trained model to a deployed autonomous system. This is the largest part, covering everything an agent needs to operate in the real world.
• Chapter 15 -- Introduction to Agentic AI: What makes a system agentic, the spectrum from chatbots to autonomous agents, and the foundational concepts for the rest of Part V.
• Chapter 16 -- RAG: Retrieval methods, chunking, embedding models, hybrid search, reranking, and production architectures.
• Chapter 17 -- Memory Systems: Working, episodic, semantic, and procedural memory for persistent agent knowledge.
• Chapter 18 -- Orchestration: ReAct, Plan-and-Execute, LLM Compiler, reflexion patterns, context management, and harness design.
• Chapter 19 -- Design Patterns: Prompt chaining, routing, parallelization, evaluation-driven orchestration, and the simplicity principle.
• Chapter 20 -- Environments and Benchmarks: WebArena, SWE-bench, OSWorld, GAIA -- evaluation environments for agentic capability.
• Chapter 21 -- Model Context Protocol (MCP): Architecture, transport layers, tool/resource/prompt primitives, security, and deployment.
• Chapter 22 -- Agent Skills: Skill libraries, tool composition, and capability abstraction.
• Chapter 23 -- A2A Communication: Google's Agent-to-Agent protocol -- Agent Cards, task lifecycle, streaming, enterprise patterns.
• Chapter 26 -- Agentic UI: Streaming interfaces, generative UI, canvas paradigms, tool visualization, human-in-the-loop patterns.
The Modern AI Pipeline
The full pipeline from base model to deployed agent:
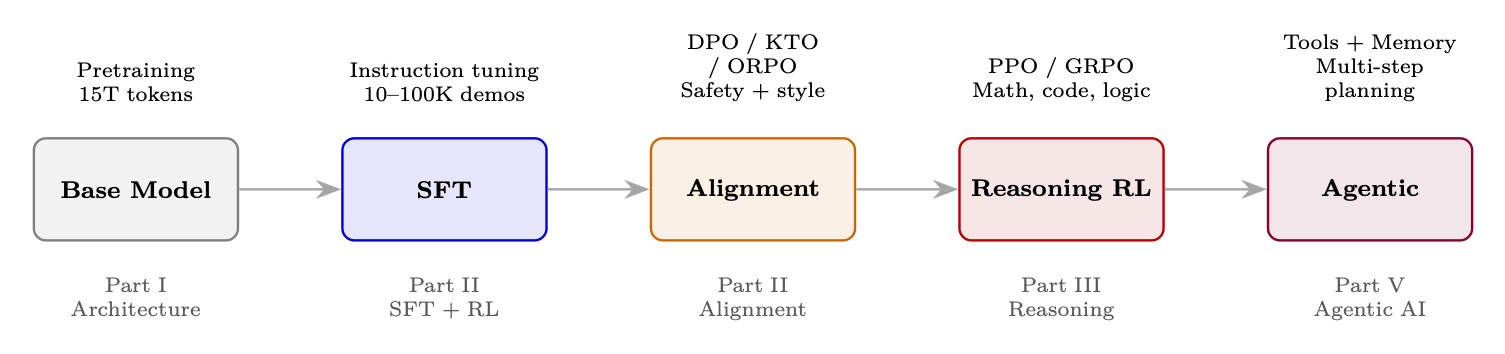
Figure 1: The modern LLM development pipeline: from pre-trained base model through alignment and reasoning to autonomous agentic capability. Each stage maps to a part of this guide.
Part I
Foundations